深度学习遭遇瓶颈
机器之心编辑部
早在 2016 年,Hinton 就曾预言,我们无需再培养放射科医生,几年过去,AI 并未取代任何一位放射科医生,这其中的问题出在哪儿?
近年来,AI 在大数据、大模型的深度学习之路上一路狂奔,但很多核心问题依然没有解决,比如如何让模型具备真正的理解能力,在很多问题上,继续扩大数据和模型规模所带来的收益似乎已经没有那么明显了。
在 Robust.AI 创始人、纽约大学名誉教授 Gary Marcus 看来,这预示着深度学习(准确地说是纯粹的端到端深度学习)可能就要“撞到南墙”了,整个 AI 领域需要寻找新的出路。
Gary Marcus 是人工智能、心理学、神经科学等多个领域的专家,他经常为《纽约客》和《纽约时报》撰稿,并且是四本书的作者,在担任纽约大学心理学和神经科学教授期间,他在人类和动物行为、神经科学、遗传学和人工智能等领域发表了大量文章,并经常刊登在 Science 和 Nature 等期刊上。
新的出路在哪儿呢?Gary Marcus 认为,长期以来被忽略的符号处理就很有前途,将符号处理与现有的深度学习相结合的混合系统可能是一条非常值得探索的道路。
熟悉 Gary Marcus 的读者都知道,这已经不是他第一次提出类似观点了,但令 Marcus 失望的是,他的提议一直没有受到社区重视,尤其是以 Hinton 为代表的顶级 AI 研究者,Hinton 甚至说过,在符号处理方法上的任何投资都是一个巨大的错误,在 Marcus 看来,Hinton 的这种对抗伤害了整个领域。
令 Marcus 欣慰的是,当前也有一些研究人员正朝着神经符号的方向进发,IBM、英特尔、谷歌、Meta 和微软等众多公司已经开始认真投资神经符号方法,这让他对人工智能的未来发展感到乐观。
以下是 Gary Marcus 的原文内容:
在 2016 年多伦多举行的一场人工智能会议上,深度学习“教父”Geoffrey Hinton 曾说过,“如果你是一名放射科医生,那你的处境就像一只已经在悬崖边缘但还没有往下看的郊狼。”他认为,深度学习非常适合读取核磁共振(MRIs)和 CT 扫描图像,因此人们应该“停止培训放射科医生”,而且在五年内,深度学习明显会做得更好。
时间快进到 2022 年,我们并没有看到哪位放射科医生被取代,相反,现在的共识是:机器学习在放射学中的应用比看起来要困难,至少到目前为止,人和机器的优势还是互补的关系。
当我们只需要粗略结果时,深度学习能表现得很好,但当我们面对风险更高的问题时,比如在放射学或无人驾驶汽车领域,我们对是否采用深度学习要更加谨慎,在一个小小的错误就能夺去一条生命的领域,深度学习还不够优秀,在遇到异常值时,深度学习系统表现出的问题尤其明显,这些异常值与它们所接受的训练有很大的不同。
目前的深度学习系统经常犯一些愚蠢的错误,它们有时会误读图像上的污垢,而人类放射科医生会认为这是一个小故障,一个深度学习系统将苹果误标为 iPod,因为苹果的前面有一张纸,上面写着 iPod,还有的系统会把一辆在雪路上翻倒的巴士误认为是扫雪机。
我们该怎么做呢?目前流行的一种选择可能只是收集更多的数据,这也是 GPT-3 的提出者 OpenAI 的明确主张,但这种方法存在严重的漏洞,现有方法并没有解决迫切需要解决的问题,即真正的理解。
我们可能已经在深度学习中遇到了扩展限制(scaling limits),或许已经接近收益递减点,在过去的几个月里,DeepMind 已经在研究比 GPT-3 更大的模型,研究表明扩大模型带来的收益已经在某些指标上开始衰减,例如真实性、推理能力和常识水平。
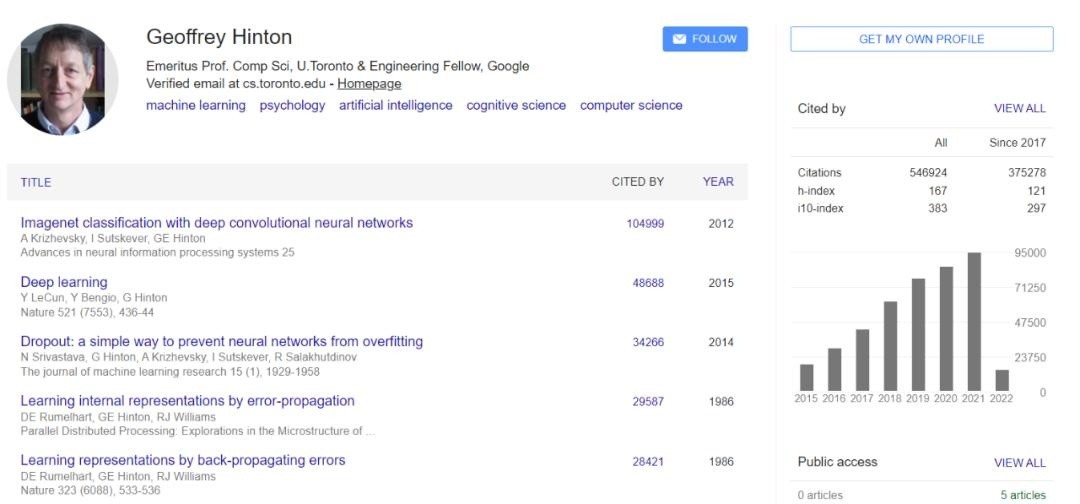
我们还需要什么?除了前文所述,我们很可能还需要重新审视一个曾经流行,但 Hinton 似乎非常想要粉碎的想法:符号处理——计算机内部编码,如用二进制位串代表一些复杂的想法,符号处理从一开始就对计算机科学至关重要,从图灵和冯诺依曼两位先驱的论文开始,它几乎就是所有软件工程的基本内容,但在深度学习中,符号处理被视为一个非常糟糕的词。
Hinton 和许多研究者在努力摆脱符号处理,深度学习的愿景似乎不是基于科学,而是基于历史的怨恨——智能行为纯粹从海量数据和深度学习的融合中产生,经典计算机和软件通过定义一组专用于特定工作的符号处理规则来解决任务,例如在文字处理器中编辑文本或在电子表格中执行计算,而神经网络尝试通过统计近似和学习来解决任务。
但符号处理不应该被忽视,符号提供了一种原则性的推断机制:符合规定的、可以普遍应用的代数程序,与已知的例子没有任何相似之处,它们(仍然是人工处理知识、在新情况下稳健地处理抽象的最佳方式。
深度学习和符号处理应该结合在一起,二进制数字(称为位)可用于编码计算机中的指令等,这种技术至少可追溯到 1945 年,当时传奇数学家冯 · 诺伊曼勾勒出了几乎所有现代计算机都遵循的体系架构,冯 · 诺依曼对二进制位可以用符号方式处理的认知是 20 世纪最重要的发明之一,你曾经使用过的每一个计算机程序都是以它为前提的。
在经典计算机科学中,图灵、冯 · 诺伊曼以及后来的研究者,用一种我们认为是代数的方式来处理符号,在简单代数中,我们有三种实体,变量(如 x、y)、操作(如 +、-)和赋值(如 x = 12),如果我们知道 x = y + 2,y = 12,你可以通过将 y 赋值为 12 来求解 x 的值,得到 14,世界上几乎所有的软件都是通过将代数运算串在一起工作的,将它们组装成更复杂的算法。

符号处理也是数据结构的基础,比如数据库可以保存特定个人及其属性的记录,并允许程序员构建可重用代码库和更大的模块,从而简化复杂系统的开发,这样的技术无处不在,如果符号对软件工程如此重要,为什么不在人工智能中也使用它们呢?
包括麦卡锡、明斯基等在内的先驱认为可以通过符号处理来精确地构建人工智能程序,用符号表示独立实体和抽象思想,这些符号可以组合成复杂的结构和丰富的知识存储,就像它们被用于 web 浏览器、电子邮件程序和文字处理软件一样,研究者对符号处理的研究扩展无处不在,但是符号本身存在问题,纯符号系统有时使用起来很笨拙,尤其在图像识别和语音识别等方面,长期以来,人们一直渴望技术有新的发展。
这就是神经网络的作用所在,神经网络在语音识别、照片标记等方面取得了不错的成就,但深度学习系统在处理以前见过的具体例子方面表现突出,但当面对新鲜事物时,经常会犯错。
处理(操纵)符号到底是什么意思?这里边有两层含义:1)拥有一组符号(本质上就是表示事物的模式)来表示信息;2)以一种特定的方式处理(操纵)这些符号,使用代数(或逻辑、计算机程序)之类的东西来操作这些符号,许多研究者的困惑来自于没有观察到 1 和 2 的区别,要了解 AI 是如何陷入困境的,必须了解两者之间的区别。
什么是符号?它们其实是一些代码,符号提供了一种原则性的推断机制:符合规定的、可以普遍应用的代数程序,与已知的例子没有任何相似之处,它们(仍然是人工处理知识、在新情况下稳健地处理抽象的最佳方式。
深度学习和符号处理应该结合在一起,在经典计算机科学中,图灵、冯 · 诺伊曼以及后来的研究者,用一种我们认为是代数的方式来处理符号,在简单代数中,我们有三种实体,变量(如 x、y)、操作(如 +、-)和赋值(如 x = 12),如果我们知道 x = y + 2,y = 12,你可以通过将 y 赋值为 12 来求解 x 的值,得到 14,世界上几乎所有的软件都是通过将代数运算串在一起工作的,将它们组装成更复杂的算法。
符号处理也是数据结构的基础,比如数据库可以保存特定个人及其属性的记录,并允许程序员构建可重用代码库和更大的模块,从而简化复杂系统的开发,这样的技术无处不在,如果符号对软件工程如此重要,为什么不在人工智能中也使用它们呢?
包括麦卡锡、明斯基等在内的先驱认为可以通过符号处理来精确地构建人工智能程序,用符号表示独立实体和抽象思想,这些符号可以组合成复杂的结构和丰富的知识存储,就像它们被用于 web 浏览器、电子邮件程序和文字处理软件一样,研究者对符号处理的研究扩展无处不在,但是符号本身存在问题,纯符号系统有时使用起来很笨拙,尤其在图像识别和语音识别等方面,长期以来,人们一直渴望技术有新的发展。
这就是神经网络的作用所在,神经网络在语音识别、照片标记等方面取得了不错的成就,但深度学习系统在处理以前见过的具体例子方面表现突出,但当面对新鲜事物时,经常会犯错。
处理(操纵)符号到底是什么意思?这里边有两层含义:1)拥有一组符号(本质上就是表示事物的模式)来表示信息;2)以一种特定的方式处理(操纵)这些符号,使用代数(或逻辑、计算机程序)之类的东西来操作这些符号,许多研究者的困惑来自于没有观察到 1 和 2 的区别,要了解 AI 是如何陷入困境的,必须了解两者之间的区别。
深度学习和符号处理应该结合在一起,在经典计算机科学中,图灵、冯 · 诺伊曼以及后来的研究者,用一种我们认为是代数的方式来处理符号,在简单代数中,我们有三种实体,变量(如 x、y)、操作(如 +、-)和赋值(如 x = 12),如果我们知道 x = y + 2,y = 12,你可以通过将 y 赋值为 12 来求解 x 的值,得到 14,世界上几乎所有的软件都是通过将代数运算串在一起工作的,将它们组装成更复杂的算法。
符号处理也是数据结构的基础,比如数据库可以保存特定个人及其属性的记录,并允许程序员构建可重用代码库和更大的模块,从而简化复杂系统的开发,这样的技术无处不在,

无限暖暖美甲金龟攻略,获取方法全解析
- 2025-06-16
- 498

无限暖暖涉火双翼详解,翅膀之火的独特魅力
- 2025-06-16
- 557

FGO国服,快速跳转从者强化界面攻略
- 2025-06-16
- 505

心动小镇手游中金毛康宝蓝的使用指南
- 2025-06-16
- 504

异域战记诺雅与塔玛拉组合之优势解析
- 2025-06-15
- 452

绝区零1.4版本剧情CG音画不同步解决方案探讨
- 2025-06-15
- 492